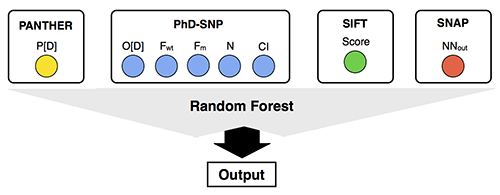
The ability of the meta-predictor approach to select high reliable prediction
has been proved calculating the accuracy of Meta-SNP on the subsets composed
by cases where all the predictions are in agreement (Consensus),
one of the two possible classes is in majority (Majority) and when half of the
methods predict one Disease and the other half Neutral (Tie).
The results shows that the accuracy of Meta-SNP increases from the Tie to the
Consensus subset (Table 2).
|
Datasets
|
Q2 |
P(D) |
Q(D) |
P(N) |
Q(N) |
MCC |
AUC |
DB |
|
All |
0.79 |
0.80 |
0.79 |
0.79 |
0.80 |
0.59 |
0.87 |
100 |
Consensus |
0.87 |
0.88 |
0.92 |
0.87 |
0.80 |
0.73 |
0.91 |
46 |
Majority |
0.75 |
0.72 |
0.64 |
0.76 |
0.82 |
0.47 |
0.82 |
40 |
Tie |
0.69 |
0.62 |
0.57 |
0.73 |
0.76 |
0.34 |
0.75 |
14 |
|
The overall accuracy Q2 is:
Q2=p/N
where p is the total number of correctly predicted
residues and N is the total number of residues.
The correlation coefficient MCC is defined as:
C(s)=[p(s)n(s)-u(s)o(s)] / W
where W is the normalization factor
W=[(p(s)+u(s))(p(s)+o(s))(n(s)+u(s))(n(s)+o(s))]1/2
for each class s (D and N, for disease-related and
polymorphism, respectively); p(s) and n(s) are the total number
of correct predictions and correctly rejected assignments,
respectively, and u(s) and o(s) are the numbers of under and over predictions.
The coverage for
each discriminated structure s is evaluated as:
Q(s)=p(s)/[p(s)+u(s)]
where p(s) and u(s) are as defined above. The probability
of correct predictions P(s) (or accuracy for s) is computed
as:
P(s)=p(s)/[p(s) + o(s)]
where p(s) and o(s) are defined above (ranging from 1 to 0).
References
[1] Capriotti E, Altman RB, Bromberg Y (2013).
Collective judgment predicts disease-associated single nucleotide variants.
mutations in proteins.
BMC Genomics. Suppl 3: S2.
[2]
Pei J, Grishin NV. (2001)
AL2CO: calculation of positional conservation in a protein sequence alignment.
Bioinformatics. 17(8):700-712.
[3]
Hall M, Frank E, Holmes G, Pfahringer B, Reutemann P, Witten IH. (2009)
The WEKA Data Mining Software: An Update.
ACM SIGKDD Explorations. 11:10-18.